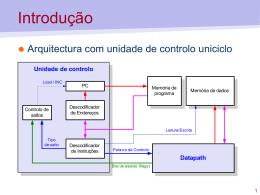
MIPS PIPELINE 1998 Morgan Kaufmann Publishers 1 MULTICICLO x PIPELINE • Multiciclo: as operações são divididas em vários estágios (S) que funcionam sequencialmente. INATIVO no ciclo 2 S2 Latch Latch Latch S1 ATIVO no ciclo 2 Sn INATIVO no ciclo 2 • Pipeline: vários estágios funcionam simultaneamente, para intruções diferentes. S2 instrução k - 1 Latch instrução k Latch Latch S1 Sn instrução k – (n -1) 1998 Morgan Kaufmann Publishers 2 Pipeline: é natural! • Exemplo de Lavanderia • Tem-se os volumes A, B, C e D de roupas para lavar, secar e passar • A lavadora leva 30 minutos • A secadora leva 40 minutos • “Passadeira” leva 20 minutos A B C D 1998 Morgan Kaufmann Publishers 3 Lavanderia Sequencial 6 7 8 9 10 11 Meia noite Tempo 30 40 20 30 40 20 30 40 20 30 40 20 T a s k A B O r d e r C D • A lavanderia sequencial leva 6 horas para 4 volumes • Se usarem o “pipeline”, quanto tempo levaria? 1998 Morgan Kaufmann Publishers 4 Lavanderia em Pipeline 6 7 8 9 10 11 Meia noite Tempo 30 40 o r d e m 40 40 40 20 A B C D • Lavanderia em Pipeline leva 3.5 horas 1998 Morgan Kaufmann Publishers 5 Lições sobre o Pipeline 6 7 8 30 40 A B C D 40 40 O Pipeline ajuda melhorar o throughput de um trabalho por completo • A taxa do Pipeline é limitada pelo estágio mais lento • Speedup ideal = Número de estágios • Comprimentos desbalanceados dos estágios do pipeline reduzem o speedup • O tempo para “preencher” o pipeline e o tempo para “limpar” o pipeline reduzem o speedup 9 Tempo o r d e m • 40 20 1998 Morgan Kaufmann Publishers 6 Pipelines em Computadores • Executa bilhões de instruções, tal que o importante seja o throughout • Speedup: para um programa de n instruções, num computador pipeline de k estágios, relativo a um computador multiciclo de k ciclos, considerando mesmo tempo de ciclo. Tempo do multiciclo = n . k .tempociclo Tempo do pipeline = (k + n-1).tempociclo Speedup = tempo do multiciclo/tempo do pipeline Speedup n.k k n 1 Para n grande, speedup ~ k 1998 Morgan Kaufmann Publishers 7 Pipeline no MIPS multiciclo pipeline 1998 Morgan Kaufmann Publishers 8 Implementação do Pipeline • O que facilita: – Todas as instruções com mesmo comprimento – Somente poucos formatos de instruções – Os operandos de memória aparecem somente em loads e stores • O que difículta: – conflitos estruturais: supor que temos somente uma memória – conflitos de controle: preocupar com instruções de branch – conflitos de dados: uma instrução depende de uma instrução prévia – Manipulação de exceções – Melhorar o desempenho com execução fora-de-ordem, etc. 1998 Morgan Kaufmann Publishers 9 Idéia Básica SOMADOR REGS. SOMADOR MEM. INSTR. ALU MEM. DADOS 1998 Morgan Kaufmann Publishers 10 Fluxo de dados com latch’s entre os estágios IF/ID somador ID/EX EX/MEM somador MEM/WB Regist. PC ALU Mem. Instr. Mem. dados 1998 Morgan Kaufmann Publishers 11 Pipelines representados graficamente Time (in clock cycles) Program execution order (in instructions) lw $10, 20($1) sub $11, $2, $3 CC 1 CC 2 CC 3 CC 4 CC 5 IM Reg ALU DM Reg IM Reg ALU DM CC 6 Reg 1998 Morgan Kaufmann Publishers 12 CONTROLE DO PIPELINE PCSrc Branch RegWrite Regs. Mem Read ALUSrc PC Mem toReg ALU Mem. Inst. ALUOp Mem. Mem dados Write RegDst 1998 Morgan Kaufmann Publishers 13 Controle do Pipeline • O que necessita ser controlado em cada estágio? – – – – – • Busca de Instrução e Incremento do PC Decodificação da Instrução / Busca de Registradores Execução Estágio de Memória Write Back Cada estágio deve funcionar para uma determinada instrução, simultaneamente a outros estágios. 1998 Morgan Kaufmann Publishers 14 Os sinais são repassados pelos estágios Controle do Pipeline como os dados Execution/Address Calculation Memory access stage control lines stage control lines Mem Mem Reg ALU ALU ALU Src Branch Read Write Op0 Op1 Instruction Dst 0 0 0 0 0 1 1 R-format lw 0 1 0 1 0 0 0 sw 1 0 0 1 0 0 X beq 0 0 1 0 1 0 X IF/ID ID/EX EX/MEM Write-back stage control lines Reg Mem to write Reg 0 1 1 1 X 0 X 0 MEM/WB 1998 Morgan Kaufmann Publishers 15 Fluxo de dados e controle PCSrc MemtoReg MemRead Branch RegWrite ALUOp MemWrite RegDst 1998 Morgan Kaufmann Publishers 16 Dependências de dados • • Pode ocorrer iniciando uma instrução antes de terminar a anterior dependências que “vão retroceder no tempo” são conflitos de dados Time (in clock cycles) CC 1 Value of register $2: 10 CC 2 CC 3 CC 4 CC 5 CC 6 CC 7 CC 8 CC 9 10 10 10 10/– 20 – 20 – 20 – 20 – 20 DM Reg Program execution order (in instructions) sub $2, $1, $3 and $12, $2, $5 or $13, $6, $2 add $14, $2, $2 sw $15, 100($2) IM Reg IM DM Reg IM DM Reg IM Reg DM Reg IM Reg Reg Reg DM Reg 1998 Morgan Kaufmann Publishers 17 Solução por Antecipação – usar os resultados temporários, sem esperar que eles sejam escritos - Atuar no caminho do banco de registr. p/ substituir o valor de leit/escrita de registrador - Antecipação da ALU Time (in clock cycles) CC 1 Value of register $2 : 10 Value of EX/MEM : X Value of MEM/WB : X CC 2 CC 3 CC 4 CC 5 CC 6 CC 7 CC 8 CC 9 10 X X 10 X X 10 – 20 X 10/– 20 X – 20 – 20 X X – 20 X X – 20 X X – 20 X X DM Reg Program execution order (in instructions) sub $2, $1, $3 and $12, $2, $5 or $13, $6, $2 add $14, $2, $2 sw $15, 100($2) IM Reg IM Reg IM DM Reg IM Reg DM Reg IM Reg DM Reg Reg DM Reg 1998 Morgan Kaufmann Publishers what if this $2 was $13? 18 Solução por Antecipação Unidade de antecipação 1998 Morgan Kaufmann Publishers 19 = = MUX A SA1 MUX A SA0 SELEÇÃO DO MUX A MEM/WBRegWrite Rt MEM/WBRegisterRd 10 EX/MEMRegWrite Rs 01 Rs 00 MUX B 10 Rt 01 EX/MEMRegisterRd 00 MUX A CIRCUITO DE ANTECIPAÇÃO (FORWARDING UNIT) = = MUX B SB0 MUX B SB1 SELEÇÃO DO MUX B 1998 Morgan Kaufmann Publishers 20 Nem sempre é possível solucionar por antecipação (Fazer o Load de uma palavra pode causar um conflito) - Se uma instrução tenta ler um registrador seguindo uma instrução de load word que escreve no mesmo registrador. Time (in clock cycles) Program CC 1 execution order (in instructions) lw $2, 20($1) and $4, $2, $5 or $8, $2, $6 add $9, $4, $2 slt $1, $6, $7 • IM CC 2 CC 3 Reg IM CC 4 CC 5 DM Reg Reg IM DM Reg IM CC 6 CC 8 CC 9 Reg DM Reg IM CC 7 Reg DM Reg Reg DM Reg Portanto, necessitamos que a unidade de detecção de conflitos 1998 Morgan Kaufmann Publishers 21 paralize, em um ciclo, as instruções seguintes ao load word Parada (Stall) manter instruções nos mesmos estágios 1998 Morgan Kaufmann Publishers 22 Unidade de detecção de conflitos • A parada faz com que uma instrução que não escreve nada prossiga 1998 Morgan Kaufmann Publishers 23 Exemplo de inserção de parada sinais 0 1998 Morgan Kaufmann Publishers 24 Conflitos de Desvio (Branch) • Quando é decidido pelo branch, outras instruções estão em pipeline! Time (in clock cycles) Program execution CC 1 CC 2 order (in instructions) 40 beq $1, $3, 7 44 and $12, $2, $5 48 or $13, $6, $2 52 add $14, $2, $2 72 lw $4, 50($7) • IM CC 3 Reg IM CC 4 CC 5 DM Reg Reg IM DM Reg IM CC 6 CC 8 CC 9 Reg DM Reg IM CC 7 Reg DM Reg Reg DM Reg O pipeline equivale a previsão de “não ocorrer branch” – Solução: hardware para desprezar as instruções posteriores 1998 Morgan Kaufmann Publishers 25 caso haja branch Controle para limpar as instruções posteriores além de antecipar o cálculo da condição IFFlush 1998 Morgan Kaufmann Publishers 26 Exemplo de beq e atualização do PC 44 and $12,$2,$5 40 beq $1,$3,7 endereço 72 lw $4, 50($7) Resulta em NOP 1998 Morgan Kaufmann Publishers 27 RESULTADO DO CONTROLE DE DESVIO Necessidade de limpar apenas uma instrução 1998 Morgan Kaufmann Publishers 28 Melhorando o desempenho • Tentar evitar paradas! P.ex., reordenar essas instruções: lw lw sw sw • $t0, $t2, $t2, $t0, 0($t1) 4($t1) 0($t1) 4($t1) Adicionar um “branch delay slot” – permitindo que a próxima instrução seguida do branch seja sempre executada – Confiar no compilador para preencher o slot com algo útil • Processador Superescalar: iniciar mais que uma instrução no mesmo ciclo 1998 Morgan Kaufmann Publishers 29 MIPS superescalar 1998 Morgan Kaufmann Publishers 30 MIPS superescalar Tipo de instrução Estágios do pipeline R ou desvio IF ID EX MEM WB Load/store IF ID EX MEM WB R ou desvio IF ID EX MEM WB Load/store IF ID EX MEM WB R ou desvio IF ID EX MEM WB Load/store IF ID EX MEM WB R ou desvio IF ID EX MEM WB Load/store IF ID EX MEM WB 1998 Morgan Kaufmann Publishers 31 EXEMPLO O código: loop: lw add sw addi bne $t0, 0 ($s1) $t0, $t0,$s2 $t0, 0($s1) $s1, $s1, -4 $s1, $zero, loop # t0 = elemento de array # soma o elemento do array a um valor escalar em $s2 # armazena o resultado # decrementa o ponteiro # desvia para loop se $s1 diferente de 0 pode ser escalonado para o MIPS superescalar da seguinte forma: R ou desvio loop: Load/store Ciclo de clock lw 1 $t0, 0($s1) addi $s1, $s1,-4 2 add $t0 , $t0, $s2 3 bne $s1, $zero, loop sw $t0, 4($s1) 4 5 instruções em 4 ciclos 1998 Morgan Kaufmann Publishers 32 Desdobramento de laço (loop unrolling) loop: R ou desvio Load/store Ciclo de clock Observações addi $s1, $s1, -16 lw $t0, 0 ($s1) 1 $s1 inicial lw $t1, 12($s1) 2 $s1 = $s1 - 16 add $t0, $t0, $s2 lw $t2, 8($s1) 3 add $t1, $t1, $s2 lw $t3, 4($s1) 4 add $t2, $t2, $s2 sw $t0, 16($s1) 5 add $t3, $t3, $s2 sw $t1, 12($s1) 6 16($s1) = $s1 inicial sw $t2, 8($s1) 7 bne $s1, $zero, loop sw $t3, 4($s1) 8 14 instruções em 8 ciclos 1998 Morgan Kaufmann Publishers 33 Escalação Dinâmica • O hardware realiza a “escalação” – O hardware tenta encontrar instruções para executar – É possível execução fora de ordem – Execução especulativa e previsão dinâmica de desvio (branch) – DEC Alpha 21264: tem 9 estágios pipeline, 6 instruções simultâneas – PowerPC e Pentium: tabela de história de desvio – É importante a tecnologia do compilador 1998 Morgan Kaufmann Publishers 34 Escalação Dinâmica Despacho em ordem Unidades funcionais Execução fora de ordem Escrita final do resultado em ordem 35 1998 Morgan Kaufmann Publishers A microarquitetura do Pentium 4 1998 Morgan Kaufmann Publishers 36
Download