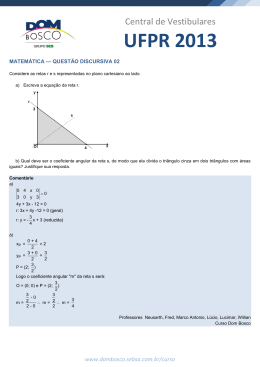
Estatística II – Antonio Roque – Aula 18 Regressão Linear Quando se consideram duas variáveis aleatórias ao mesmo tempo, X e Y, as técnicas estatísticas aplicadas são as de regressão e correlação. As duas técnicas estão relacionadas, mas são usadas para diferentes propósitos. O objetivo mais comum da análise de regressão é obter uma equação que possa ser usada para prever ou estimar o valor de uma variável em função de um dado valor de uma outra variável. A análise de correlação, por outro lado, é usada para se obter uma medida do grau ou da força da associação entre duas variáveis. Em uma análise de regressão, dadas as duas variáveis que serão estudadas, deve-se definir qual será considerada como a variável dependente e qual será a variável independente. A variável independente, que costuma ser denotada por X, é a que vai determinar o comportamento da outra variável, por isto chamada de dependente, denotada por Y. A variável dependente (Y) é aquela que queremos estudar e a variável independente (X) é aquela que, segundo nossa hipótese, causa alguma modificação em Y. Em textos de economia costuma-se chamar a variável independente de exógena, porque ela está fora do sistema em estudo, e a variável dependente de endógena, porque ela faz parte do sistema em estudo. Em muitos casos é fácil determinar, entre duas variáveis, qual deve ser a independente e qual será a dependente. Se, por exemplo, há o interesse em estudar o consumo de guloseimas (balas, biscoitos e chocolates) por família em uma dada região e se quer relacionar esse consumo com a renda familiar, vemos que a variável dependente deve ser o consumo de guloseimas por família e a variável independente deve ser a renda da família, pois seria absurdo supor que é o consumo de guloseimas que determina a renda de uma família. 1 Estatística II – Antonio Roque – Aula 18 Agora, em um caso em que se quer estudar as variáveis “vendas de jornais sensacionalistas” (tipo Notícias Populares) e “vendas de bebidas alcoólicas” em uma dada região fica mais difícil decidir qual deve ser tratada como dependente e qual como independente. Em casos como este a decisão sobre qual variável será a dependente e qual será a independente depende do modelo teórico ou da interpretação adotada pelo investigador, mas isto não irá influenciar os métodos de regressão e correlação descritos a seguir. Regressão linear simples Como exemplo introdutório da análise de regressão, vamos considerar dados relacionando pressão sangüínea sistólica com nível de dosagem de uma droga anti-hipertensão. Nível de dosagem da droga Pressão sangüínea sistólica média (mg) (mm Hg) 2 278 3 240 4 198 5 132 6 111 Olhando para os dados, vemos que alguma relação existe entre eles: quanto maior o nível de dosagem, menor a pressão sangüínea. Estes dados estão mostrados no diagrama de dispersão abaixo. Observe que nem todos os pontos caem exatamente sobre uma linha reta, mas a tendência é que os valores de Y decresçam de uma maneira aproximadamente linear à medida que os valores de X cresçam. Isto indica que a relação entre Y e X pode ser linear e pode ser descrita por uma linha reta. Vamos tentar determinar uma “equação” para essa reta. 2 Pressão sangüínea sistólica Estatística II – Antonio Roque – Aula 18 300 250 200 150 100 50 0 1 2 3 4 5 6 7 Nível de dosagem da droga anti-hipertensiva Diagrama de dispersão para os dados da tabela acima. Qualquer linha reta tem a forma geral: Y = a + bX , onde b dá a inclinação da linha e a é o ponto onde a linha cruza o eixo Y. Para quaisquer dois pontos, é fácil determinar a linha reta que os une; porém, para três ou mais pontos, como no caso em questão, é em geral impossível encontrar uma linha reta que passe por todos os pontos. Neste caso, o que se tenta fazer é encontrar a linha reta que melhor represente a configuração dos pontos. Uma ilustração disto é dada pelo gráfico abaixo: O chapéu sobre o Y, (Ŷ), indica que a reta da figura, cuja equação é Yˆ = a + bX , é uma estimativa para a hipotética reta verdadeira. As distâncias dos pontos para a linha são dadas por: d i = Yi − Yˆi , onde Yˆi = a + bX i . A reta Ŷ = a + bX tenta minimizar as distâncias (ou desvios, ou ainda resíduos) d i dos pontos para ela: pode-se perceber isto visualmente. Para o gráfico acima, d1 é positiva, d 2 é negativa e d 3 é positiva. Poderíamos somar as três distâncias e tentar encontrar alguma maneira matemática de minimizar seu valor. Porém, é comum que desvios em torno de algum valor se anulem quando somados, como no caso do desvio médio. 3 Estatística II – Antonio Roque – Aula 18 Para se medir o grau de adequação (ou ajuste) de uma linha reta a um conjunto de pontos, é mais conveniente calcular a soma dos quadrados dos desvios. Esta é sempre uma quantidade positiva e é a que se costuma usar para medir o ajuste dos pontos pela reta: ( ). ∑ d i2 = ∑ Yi − Yˆi 2 O método usado para se encontrar a reta que mais se ajuste a um conjunto de pontos utilizando a fórmula acima é chamado de método dos mínimos quadrados e a reta calculada é chamada de reta de regressão. O método é chamado de “mínimos quadrados” porque o seu objetivo é encontrar a reta Ŷ que minimize a soma dos quadrados da equação. A discussão formal deste método não será feita aqui. Apenas os seus princípios serão dados. Para uma dada reta Yˆ = a + bX , a soma dos quadrados dos desvios é escrita como ( Φ = ∑ Yi − Yˆ ) = ∑ (Y 2 i − a − bX i ) . 2 Esta somatória pode ser vista como uma função dos parâmetros a e b, pois variando-se os valores de a e de b altera-se o valor da soma dos quadrados dos desvios. Note que a forma funcional desta função é a de um parabolóide (veja a figura abaixo), pois a dependência de maior ordem em a e b é quadrática, de maneira que existe um par (a, b) para o qual ela tem um valor mínimo. 4 Estatística II – Antonio Roque – Aula 18 Pela teoria dos máximos e mínimos do Cálculo, o ponto de mínimo (a, b) é determinado pela condição de que ele seja um extremo, ou seja ∂Φ ∂Φ =0 e = 0. ∂a ∂b Calculando as derivadas chega-se a um sistema de equações algébricas com duas incógnitas, a e b. Resolvendo esse sistema de equações chega-se aos valores de a e b: b= ∑ (X i i − X )(Yi − Y ) ∑ (X − X) ; 2 i i a = Y − bX , onde X e Y são as médias dos valores de X e Y, respectivamente. Há uma fórmula mais simples para o cálculo de b, que pode ser obtida expandindo-se os termos entre parênteses. O resultado (tente obtê-lo como exercício) é: b= n∑ X i Yi − ∑ X i ∑ Yi n∑ X i2 − ∑ X i i i i i i 2 , onde n é o número de pares de pontos. Voltando agora ao exemplo sobre pressão sangüínea sistólica, temos que a reta de regressão que melhor se ajusta à amostra de pontos ( X i , Yi ) é dada por Ŷ = a + bX onde a e b são dados pelas fórmulas acima. Para calcular a reta de regressão devemos montar uma tabela como a mostrada abaixo: 5 Estatística II – Antonio Roque – Aula 18 Dados para o cálculo da linha de regressão para nível de dosagem da droga (X) e pressão sangüínea sistólica (Y): n X Y X2 Y2 1 2 278 4 77284 556 2 3 240 9 57600 720 3 4 198 16 39204 792 4 5 132 25 17424 660 5 6 111 36 12321 666 X.Y Soma 20 959 90 2038333394 A partir dos valores da tabela, calculamos: Y = ∑ Y 959 = = 191,8 ; n 5 b= X = ∑ X 20 = = 4 ,0 n 5 5.3394 − 20.959 2210 = − = −44,2 ; 2 50 5.90 − 20 a = Y − bX = 191,8 − (− 44 ,2 ) 4 ,0 = 368,6 Ŷ = 368,6 − 44,2 X Ŷ=368,6 – 44,2 X Gráfico de Ŷ=368,6- 44,2X 6 Estatística II – Antonio Roque – Aula 18 Conhecendo-se a equação para a reta, ela pode ser traçada determinando-se 2 pontos. Por exemplo, para X = 2 e X = 7 a equação dá, respectivamente: Ŷ = 280,2 e Ŷ = 59,2 . É assim que se traçou o gráfico acima. Note que a reta traçada representa bem os pontos do gráfico de dispersão, pelo menos visualmente. Para medirmos a força desse ajuste linear entre as duas variáveis, devemos calcular o coeficiente de correlação de Pearson entre elas. A variância em torno da linha de regressão Assim como se pode definir uma variância (ou desvio padrão) de um conjunto de pontos em torno de seu valor médio Y , também se pode definir uma variância (ou desvio padrão) de um conjunto de pontos ordenados Yi em torno da sua linha de regressão Ŷ. Esta 2 quantidade, denotada por S XY , é definida como ∑ (Y i S 2 XY = − Yˆ i n−2 ) 2 , e a sua raiz quadrada, chamada de erro padrão da previsão, é dada por 2 S XY = S XY . Esta última quantidade é análoga ao desvio padrão visto nas aulas de estatística descritiva. Ela dá uma medida do desvio “médio” dos valores observados Yi em relação ao valor 2 predito Ŷ pela linha de regressão. Note que a única diferença da definição de S XY para a da variância usual é que se dividiu por n − 2 ao invés de por n − 1. Para um conjunto grande de dados a computação de cada (Yi − Yˆ ) é trabalhosa quando deve 2 ser feita manualmente. Existe, porém, uma fórmula algebricamente equivalente par S XY que simplifica os cálculos: ∑ (Y i 2 S XY = i − Y ) − b 2 ∑ (X i − X ) 2 2 n−2 . 7 Estatística II – Antonio Roque – Aula 18 Com o uso da tabela para os dados de pressão sistólica temos: 19904,4 − (− 44,2 ) × 10 368,0 2 = = 122,7 ⇒ S XY = S XY = 11,1 5−2 3 2 2 S XY = Da fórmula acima, vê-se que a variância em relação à reta Ŷ é igual à variância em relação à média Y se b = 0 (inclinação nula) e se n for muito grande, de maneira que n − 2 ≅ n − 1. Exercícios Exemplo 1. Predizer a nota média de um estudante de uma universidade ao final do seu primeiro ano com base na sua nota média do exame vestibular. Seleciona-se uma amostra de interesse (por exemplo estudantes de Biologia da USP/Ribeirão) e toma-se suas notas médias no vestibular e no primeiro ano da universidade. Constrói-se uma tabela, um diagrama de dispersão e, caso se desconfie que haja uma relação linear, determina-se a linha de regressão e o coeficiente de correlação. Média do vestibular Média do primeiro ano (X) (1≤C.R.≤5) (Y) 1 24 1,5 2 61 3,5 3 30 1,7 4 48 2,7 5 60 3,4 6 32 1,6 7 19 1,2 8 22 1,3 9 41 2,2 10 46 2,7 Estudante 8 Y = ∑ Yi = 21,8 = 2,18 ; 10 Estatística II – Antonio Roque – Aula 18 ∑ X = 383 = 38,3 X = 10 10 10 ∑ (X − X ) = 2098,1 ; ∑ (X − X )(Y − Y ) = 116,16 ∑ (Y − Y ) 2 2 = 6,54 Com o auxílio dos dados obtidos: b= ∑ (X − X )(Y − Y ) = 116,16 = 0,05 , 2098,1 ∑ (X − X ) 2 a = Y − b X = 2,18 − (0,0554)(38,3) = 0,06 . Então: Yˆ = 0,06 + 0,05 X Diagrama de dispersão para os dados do exemplo Variância em torno de Ŷ: S 2 XY ∑ (Y = − Y ) − b 2 ∑ (X i − X ) 2 y 2 n−2 = 6,54 − (0,05) (2098,1) = 0,012 ⇒ 8 2 = 9 Estatística II – Antonio Roque – Aula 18 2 = 0,11 ⇒ Erro padrão da previsão = S XY = S XY Coeficiente de correlação: r= ∑ ( X − X )(Y − Y ) = 2 2 ∑ (X − X ) ∑ (Y − Y ) 116,16 (2098,1)(6 ,536 ) = 0,99 (forte relação linear positiva) Um estudante com média no vestibular = 40 teria, de acordo com a análise de regressão feita, C.R. no 1º ano = Ŷ = 0,06+0,05 (40) = 2,27. 2. A tabela abaixo fornece os valores médios, antes da 2ª Guerra Mundial, da ingestão diária de calorias e da taxa de mortalidade infantil para alguns países selecionados. Países Nº de calorias por pessoa por dia (X) Taxa de mortalidade infantil por 1.000 (Y) Argentina 2.730 98,8 Burma 2.080 202,1 Ceilão 1.920 182,8 Chile 2.240 240,8 Colômbia 1.860 155,6 Cuba 2.610 116,8 Egito 2.450 162,9 Índia 1.970 161,6 Uruguai 2.380 94,1 a) Faça o diagrama de dispersão para estes dados; b) Calcule a reta de regressão para os dados e desenhe-a no diagrama; c) Calcule o coeficiente de correlação. X = 2249 ; Y = 157 ; ∑ ( X − X )(Y − Y ) = −67163 ; 10 Estatística II – Antonio Roque – Aula 18 2 ∑ (Y − Y ) = 18740 . 2 ∑ ( X − X ) = 785289 ; b= 67163 ∑ ( X − X )(Y − Y ) =− = −0 ,0855 ; 2 785289 ∑ (X − X ) a = Y − bX = 157 − (− 0,0855) × 2249 = 349 ; r= Ŷ = 349 − 0 ,0855 X̂ − 67163 − 67163 ∑ ( X − X )(Y − Y ) = = = −0 ,5536 2 2 785289 × 18740 121311 ∑ (X − X ) ∑ (Y − Y ) 250 230 210 190 170 Reta de Regressão 150 130 110 90 1800 2000 2200 2400 2600 2800 3. Os lucros de uma companhia no período de 1990 a 1994 são dados abaixo. Obtenha a reta de regressão e o coeficiente de correlação para os dados. Com base na reta obtida, estime o lucro para 1995. Ano (t) Lucro X (milhões (X − X ) (Y − Y ) (X − X )2 (Y − Y )2 (X − X ) (Y − Y ) US$) 1990 0 2,3 -2 1991 1 2,9 -1 1992 2 5,2 0 1993 3 5,8 1994 4 6,1 - 4 4,67 4,32 1 2,43 1,56 0,74 0 0,55 0 1 1,34 1 1,80 1,34 2 1,64 4 2,69 3,28 2,16 1,56 11 Estatística II – Antonio Roque – Aula 18 Quando uma das variáveis é o ano, não é conveniente usá-la para fazer os cálculos (isso os tornaria muito trabalhosos). É mais fácil definir uma outra variável X a partir do tempo em anos. Por exemplo, aqui escolheu-se o ano de 1990 como o ano para o qual X = 0. A partir daí, acrescenta-se 1 à variável X para cada ano. Portanto: X = 10 / 5 = 2 ; ⇒ ∑ (X − X )(Y − Y ) = 10 ,50; ⇒b = Y = 22,3 / 5 = 4,46 2 ∑ (X − X ) = 10; 10 ,5 = 1,05; 10 ⇒ 2 ∑ (Y − Y ) = 12,14 ⇒ a = Y − bX = 4 ,46 − 1,05 × 2 = 2 ,36 ⇒ ⇒ Ŷ = 2 ,36 + 1,05 X r= 10 ,50 10 × 12 ,14 = 10 ,50 = 0 ,9528 11,02 A estimativa de lucros para 95 é: 1995 → x = 5 ⇒ Ŷ = 2 ,36 + 1,05 × 5 = 7 ,61 Lucro (milhões US$) 7 6 5 4 3 2 90 91 92 93 94 95 Ano 12
Download